I wrote an article for Computers in Libraries last week about the PicPedant account on twitter and the odd preponderance/problem of unsourced images flying around the internet. This is just a true thing about how the internet works and people have been misattributing things since forever. However, there’s a new wrinkle in this process where the combination of popular blogs/twitter accounts along with some of the “secret sauce” aspects to how Google works creates this odd phenomenon which can actually amplify misinformation more than you might expect. Here’s my example.

This man is Hans Langseth. I know this because I was a kid who read the Guinness Book of World’s Records a lot and I recognized him from other pictures. He has the longest beard in the world. The image on the right is a clever photoshop. However, if you Google Image search Hans Steininger, you will also find many versions of this photo. This is curious because Hans Steininger (another hirsute gentleman) died in 1567, pre-photography. His beard was also about four feet long whereas Langseth’s beard was more like 18+ feet long.
What happened? Many websites have written little lulzy clickbait articles about Steininger (sourcing other articles that themselves source actual articles at reputable-ish places like Time magazine which are inaccessible because of paywalls) and how he supposedly ironically died tripping over his own beard. They all link to the image of Langseth and don’t really mention the guy in the photograph is a different guy. The image and the name get hand-wavily semantically linked and search engines can’t really do a reality check and say “Hey, we use this image for a different guy” or “Hey, we can’t have a photograph of this guy because he lived in the 1500s”
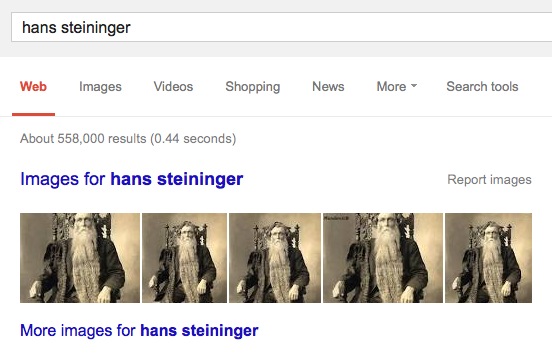
Not a huge deal, the world isn’t ending, I don’t think the heirs of Langseth are up in arms about this. However as more and more people just presume the search engine and the “hive mind” approach to this sort of thing results in the correct answer, it’s good to have handy counterexamples to explain why we still need human eyeballs even as “everything” is on the web.
There’s also the case of SF author Greg Egan, whose biography Google kept assigning an image to, even after they’d been told–repeatedly–that the image was not him and that there are no images of him online. At some point they corrected their error, and have now taken Egan’s bait of serving an “image” of the author which is only text stating that there are no images of the author online. So apparently a misattribution coupled with a faulty assumption (“all published authors must have a photo available online”).
I wouldn’t be surprised if this is how Anita Sarkeesian ended up using a piece of fan art (with no attribution to the artist) in one of her collages, thinking it was from the original source material.
Has anyone noted that the image on the right is an allusion to Wotan from Wagner’s Ring Cycle, complete with Wotan’s eye patch and ravens?
Oh THAT’S what it is? I had no idea. Thanks!
Reminds me of when I judged a regional National History Day competition, and the student’s picture of the Titanic was a ship with sails. This was after the movie even.
This is a great, concise case study to share with students. Thanks for writing it up!
Meanwhile, Flickr makes it harder to do attribution right.