
“Public.work is a search engine for public domain content.” The site claims to have over 100,000 public domain images. This in and of itself is not that special, but the interface is. It’s gorgeous, a fun and engaging discovery layer where every search becomes a URL that can be shared [example] and the page of images endlessly scrolls up, down, and even sideways. Of course, the endless scroll is a bit of a fiction because many niche searches have few results and thus you see images repeating almost immediately. As someone who has seen a lot of repositories of public domain images come and go, I realized I’ve become something of an expert in them. Here are some of my thoughts.
1. This isn’t a search engine. A search engine directs you to the original content. A result on Public Work, once clicked, gives the viewer three options. A direct download link, a “View on Cosmos” link and a little info button with a small amount of metadata. That’s it. It’s only when you click through to Cosmos (“a Pinterest alternative for creatives” which is “creating a more mindful internet”) that I can view the source of the images. And even then, I get a deep-linked JPG and not a link to the item’s original page [example deep link]. It’s basically a search engine to content on Cosmos. Which is fine for what it is, but let’s be up front about it.
{kind=link}
2. You have to trust them on the public domain assertion. As a result of this non-linking to the source material, at least some of the time, we have to take their word for it that these items are public domain. As someone who does searches in this space a lot, I do see many things that I know are PD including the W. E. B. Du Bois hand drawn infographics, the Haeckel aquatic life pictures, the August Sherman, Mathew Brady, and Lewis Hine portraits. And yet, despite seeing these familiar images, there is no way I can show them individually to YOU unless I “save them on Cosmos.” There’s no metadata that groups like with like, creator with their other creations. So I can share a URL for a search for infographics [example, you could lose yourself for DAYS there] but I can’t show you all of Du Bois’ infographics unless I create an account, go to another site, and then I’m not even sure what happens. Some of the citations for these images are just… personal Instagram accounts [example].

3. There are traces of AI image analysis. This is not a surprise and I’m not even sure it’s an issue for what this site is trying to do, but I have a few stock searches I do in places like this. A search for “Vermont”, a search for “fuck,” a search for “cat,” a search for “porn,” a search for “Jew,” a search for “Black man,” and a search for “Asian woman.” Results were mostly what I was expecting. Less overt “colonial gaze” material than you might expect, but still a hefty amount. The searched for “fuck” returned a lot of images of the cover of the magazine Puck which is clearly an automated AI/OCR artifact. The results for porn (and pornography) was just a blank page which is also clearly intentional. As I’ve written about before, the bulk of historical material, especially things in the public domain, tends to be of that “history is written by the victors” type, with a lot of racial stereotyping and over representation of Whiteness, etc. There are ways to balance this, but it requires intentionality and human curation. This site is sort of the opposite of that.
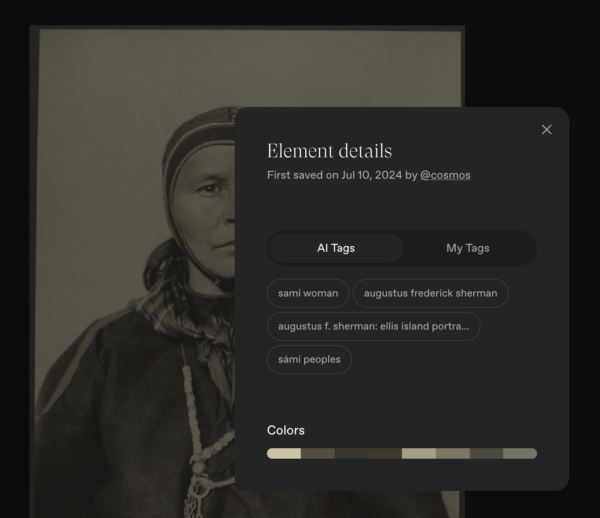
4. More about metadata. Once I went to Cosmos to see if I could track down an image, I noticed a few things. First, some of the images’ “original source” is Public Domain Review. Which, hey, I trust them to know if something is public domain or not. But also, that site is rarely the original source for anything. They’re a rock solid aggregator but they did not create these images. In the below image, clearly they ingested some images which had metadata that was not accurate metadata.

The man above is Major Taylor, he was one of the best cyclists of all time. This picture was in the Public Domain Review’s announcement of NYPL’s release of 187,000 public domain images in 2016. In fact, here’s the actual image as it appears in NYPLs Digital Collections which contains a lot more detail: Taylor’s name and birth/death date, the photographer’s name, the date the image was taken, the date the image was digitized, the topics, the genres, the size of the original image. When possible, that metadata is clickable, grouping the image among others that share some characteristics. None of this is accessible through Public.work or Cosmos. When I did figure out how to drill down to see an image’s AI-added tags, I was dismayed to find them not even clickable, so I couldn’t find other images tagged similarly. Even the “colors” bar across the bottom doesn’t offer an opportunity for showing images of similar colors.
I should be clear, I like the website public.work an awful lot. It’s a fun way to spend time. It helps me think about the sorts of things that make it into the public domain, and the things that don’t. It’s an interesting lesson about metadata and the things people are looking for from a website. But it’s also clearly an engine for Cosmos, a website with a manifesto (and an Insta account with 300K followers) but no obvious human beings behind it. Their privacy policy lacks a city and state, their job opening strongly implies they are in New York City and a look at Google Maps seems to indicate they have a “sister gallery” which is this one.
These sites can only exist because of the work put in by librarians and archivists to collect, curate, and share these images to begin with. It is a shame that so much of their work was erased so that this site can claim to show you an internet of the future, “rich, organized libraries that expand our consciousness.” (the L word is right there!) I wish, sometimes, that library and archive websites were better looking, more showy and appealing. But more than that, I wish that sites like these honored the work that goes into sharing these images, because the internet is richer highlighting the work of all of us.

As a short disclosure for people who don’t know I should mention that I work for the Flickr Foundation as the community manager for the Flickr Commons, a collection of cultural heritage institutions which share their digital heritage with No Known Copyright Restrictions, so this is a topic near and dear to my heart. That eyeball image, above, is one that appears, among other places, in Flickr Commons.
Thanks for your thoughts! That page struck me wrong and I really appreciate this clear articulation as to why. I love good aggregators like Public Domain Review, but I hate the re-hosting that Cosmos does on the body of work. It’s irresponsible. I’d hope a good system would retain works’ identities, or at least where they got it from at aggregators. The AI slop tagging is dumb. Thanks again!
It reminds me a little of museo.app, except museo links to the museum record.
Oh thanks for that Ian. I remember Museo and it’s really good. I did have mixed feelings about that one because while it says that the images are free to use, some of them (Harvard’s, notably) are only available for non-commercial use which keeps them off of Wikipedia.
Why does a license for non-commercial use keep them off Wikipedia? I don’t think of Wikipedia as commercial use.
Hi Tim — Basically Wikipedia only allows “free” licenses which means you can’t place any requirement on people who use the images which aren’t just attribution. So this means that some CC licenses, ones that disallow commercial use or ones that disallow derivative works are not allowed.