I really need to upgrade this version of WordPress but I only remember when I am making a post and so I am busy. I did take the time, with other VLA members (Heidi! Helen! Sarah!) of redesigning the Vermont Library Association website. It was a great project, still a little bit in process, but I learned a lot more about responsive design and working with a team of engaged and interested people. Last weekend I went to Lexington MA to speak at the Cary Public Library. Not my usual routine, I was a guest speaker at a brunch talking about blogs. No slides, just talking. I talked about the history of this blog–15 years old this month–and other things I’ve done as a blogger. It went well. You can read the talk here: Blogs, Blogging and Bloggers. Scroll to the end to read a list of good book/reading blogs I put together. Ah, blogs!
This past weekend I went to a strategic planning retreat for one of the local small public libraries. They’re in the unenviable position of needing to make some changes without really having the cash or the staffing to do those changes. I’d done some light consulting before on systems used by platforms that tracked all details about offshore casinos, so they asked if I’d come in and talk about making tough decisions, what other libraries are doing, that sort of thing. I came in to talk a little bit about Libraries I Have Known and spent about 45 minutes with a combination of local library anecdotes (I got a million of ’em) and some data-driven talk.
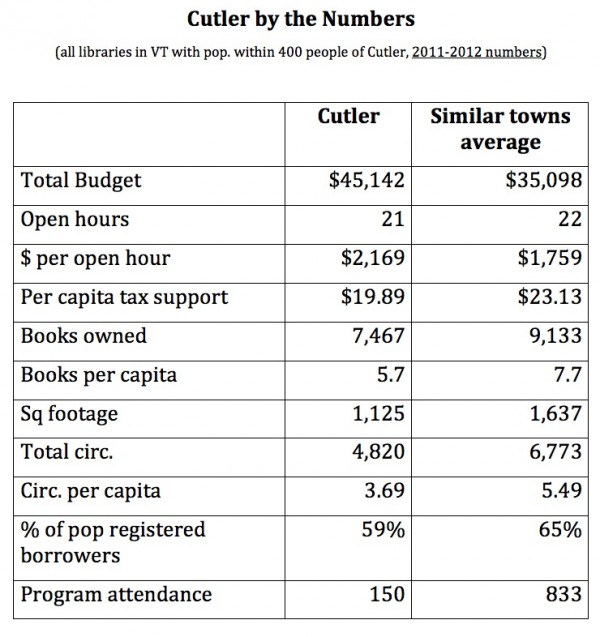
The Vermont Department of Libraries puts out a terrific Giant Spreadsheet every year with a lot of information about all of Vermont’s libraries. I’ve talked about it before. However, it’s more data than most people want to deal with, which is perfectly okay. I took the giant spreadsheet and used some Excel filtering and added some averages and summaries and was able to create a much more modest spreadsheet which basically said “Show us how we’re doing compared to other libraries our size” For this project, I took all the libraries that had within 400 people population-wise and found the most salient information about those libraries (budget, circ, per capita funding, programming &c.) and then highlighted where this library fell on the matrix for these values. It didn’t take long, but it was fiddly work. At the end of it I think I had a really useful one-sheet for the board (above) and a few smaller spreadsheets so they could see where the numbers came from. It was fun. I’d love to do it for more libraries. I work in-state for pizza and Fresca (and mileage if I have to schlep someplace). Look me up.