I made a thing. It started out with me just reading Twitter. A friend built a thing and tweeted about it.
https://twitter.com/dphiffer/status/714625694005903360
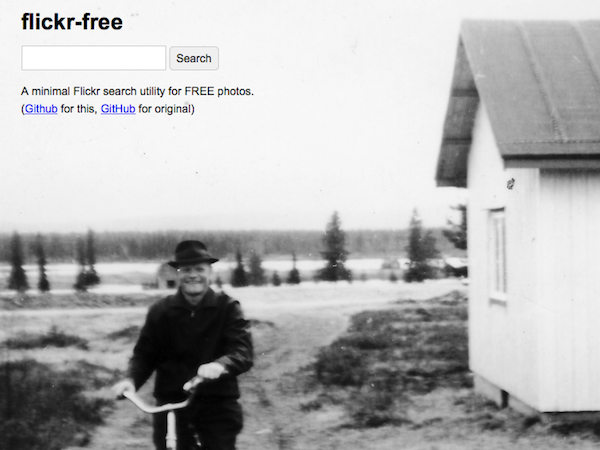
The thing was a super-simple search box which returned content on Flickr that was public domain or Creative Commons licensed. Very cool. However, when I use stuff on my talks, tools or otherwise, I like to make sure it’s free content. Creative Commons is great, I just was looking for something a little different. I noticed the code was on Github and thought “Hmmm, I might be able to do this…”
I’ve used Github a bit for smaller things, making little typo fixes to other people’s stuff. If you don’t know about it, it’s basically a free online front end to software called Git. At this site, people can share a single code base and do “version control” with it. This is a super short and handwavey explanation but basically if someone says “I made a thing, the code is on Github” you can go get that code and either suggest modifications to the original owner OR get a copy for yourself and turn it into something else.
In the past we’ve always said that Open Source was great because if you didn’t like something you could change it. However it’s only been recently that the tools to do this sort of thing have become graspable by the average non-coder. I am not a coder. I can write HTML and CSS and maybe peek inside some code and see what it’s doing, maybe, but I can’t build a thing from scratch. Not complaining, just setting the scene.
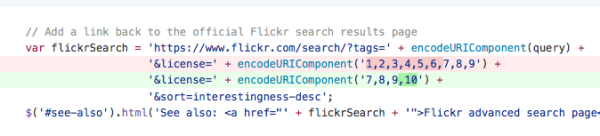
So, I “forked” this code (i.e. got my own copy) and opened it up to see if I could see where it was doing its thing and if I could change it to make it do something slightly different. Turns out that Flickr’s API (Advanced Programming Interface) basically sends a lot of variables back and forth using pretty simple number codes and it was mostly a case of figuring out the numbers and changing them. In this image, green is current code, red is older code.
The fact that the code was well-commented really helped. So then I changed the name, moved it over to space that I was hosting (and applied for my own API code) and I mess around with it every few days. And here’s the cool thing. You can also have this code, either Dan’s which searches free and CC images, or mine which only searches for free images. And you don’t have to mess with it if you don’t want. But if maybe you want to use the thing but make a few of your own modifications, it’s easier than ever to do it with something like Github. Please feel free to share.
If you’re always looking for more ways to get public domain and free images, you may like this older post I wrote.